1. 概述
中国科学院高能物理研究所计算中心成立于 1974 年,经过 30 多年的发展,现拥有国内领先的高性能计算平台,包括世界一流的网格站点、大型异构的计算集群、技术先进的存储系统。计算平台服务于BESIII 、大亚湾中微子、江门中微子、HXMT等国内主导的高能物理及天体物理实验离线数据处理、并为高能光源设计、加速器物理研究、理论物理研究、分子动力学及量子化学等研究提供计算服务,计算平台还积极参与国际大型高能物理实验LHC的计算支持。 目前计算中心的高性能计算平台包括13,500 CPU 核规模的高吞吐量HTCondor计算集群、0.5PFlops的混合GPU与CPU的SLURM计算集群、连接世界各地计算资源的分布计算系统,以及虚拟化计算系统和Hadoop计算集群;总存储量近20PB,包括13PB 的磁盘空间和7PB 的磁带存储。计算平台的网络带宽达到 20GB。除了本地计算集群以外,还提供机器学习运行平台、志愿计算等多种服务。
以下是快速入门流程:
Step 1 账号申请
用户首先需要拥有计算环境用户账号后才能使用计算环境资源。详情可参见账号申请。
Step 2 账号登录
登录结点是用户使用计算资源,调试程序、提交作业的唯一接口。用户用申请的账号和密码连接lxlogin.ihep.ac.cn。
- Linux用户
使用linux系统的用户从自己的linux操作系统的字符终端直接用ssh命令登录lxlogin.ihep.ac.cn:
$ ssh –l username lxlogin.ihep.ac.cn
根据提示输入正确密码,即能成功登录进入lxlogin机器上的个人账号。
- Windows用户
使用windowns操作系统的用户需要安装ssh登录软件,如putty或SSH Secure Shell Client 等。
以SSH Secure Shell Client为例来描述连接lxlogin.ihep.ac.cn的过程:
a.下载后SSH Secure Shell Client软件,安装成功后运行SshClient.exe文件,将弹出
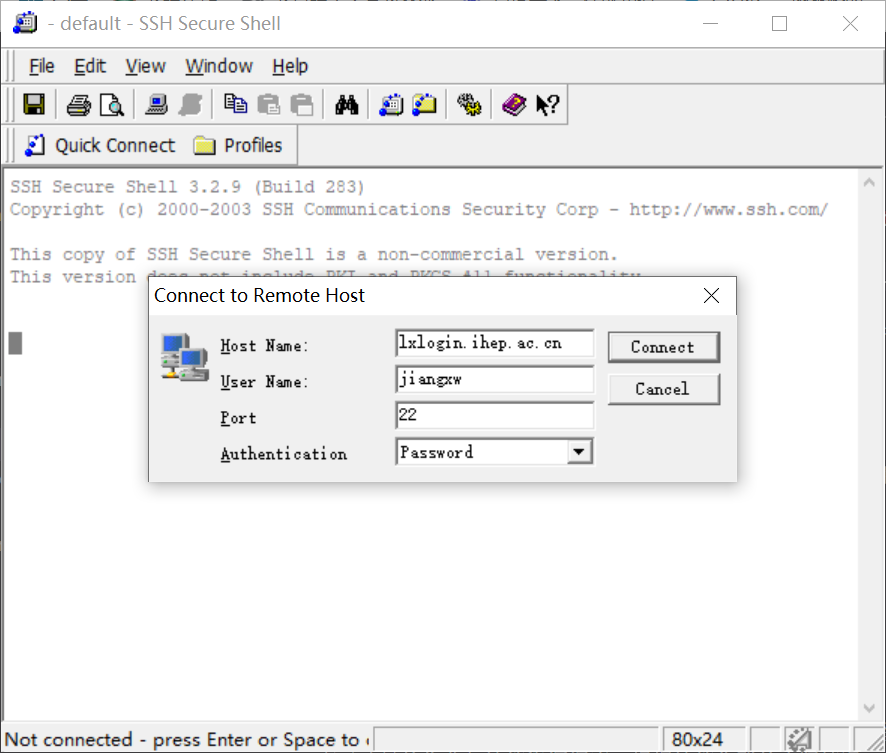
b.在Host Name一栏里填写”lxlogin.ihep.ac.cn”后,用鼠标点击“Connect”按钮。按照屏幕提示输入密码即可成功登录。
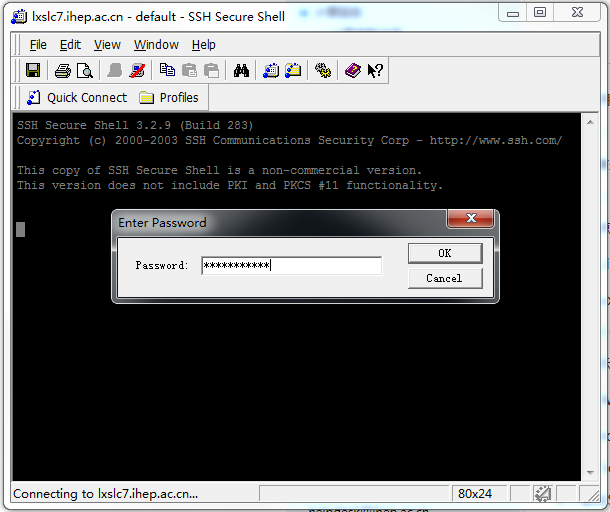
Step 3.1 HTCondor作业
HTCondor是一款在高能物理计算领域较流行的开源批处理系统,支持大规模计算集群,具有较高灵活性,特别适用于高能所高吞吐量的作业与计算资源调度。根据计算集群的实际情况,计算中心优化HTCondor功能与性能以及开发集中管理、监控等配套系统,部署实施了基于HTCondor的高吞吐量调度系统。目前HTCondor系统支持BES、JUNO、DYW、LHAASO、HXMT等高能所绝大部分实验。
为了方便用户使用计算系统管理作业,计算中心提供hepjob作业管理工具,用来完成作业提交、查询、删除等操作.
说明:HepJob涉及的所有命令都在以下目录,建议将该目录加入用户环境变量 PATH 中 (注意更改操作系统对应的版本,例如,在sl6操作系统下请使用hep_job.sl6):
- bash 用户
$ export PATH=/afs/ihep.ac.cn/soft/common/sysgroup/hep_job/bin/:$PATH
- tcsh 用户
$ setenv PATH /afs/ihep.ac.cn/soft/common/sysgroup/hep_job/bin/:$PATH
提交 HTCodor 计算集群的作业文件必须具备可执行权限。可使用以下命令查看和赋予文件权限:
- 查看文件权限
$ /bin/ls –l job.sh
-rw-r--r-- 1 jiangxw u07 85 Aug 29 18:23 job.sh
上面的例子中 job.sh 不具有可执行权限,执 行如下命令可赋予文件可执行权限
$ /bin/chmod +x job.sh
再次查询,首列输出信息中多出的‘x’表示可执行权限
$ /bin/ls –l job.sh
-rwxr-xr-x 1 jiangxw u07 85 Aug 29 18:23 job.sh
作业提交
$ hep_sub job.sh -g group_namejob.sh是用户提交的作业脚本,group_name是用户想要使用的资源所属的用户组。其中,-g参数指明的用户组,可以使用hep_sub -h命令查看-g说明信息中,哪些组可以指定。
作业查询
(1)根据用户查询作业状态。例如,查询用户user1的作业状态,执行如下命令:
$ hep_q -u user1执行该命令,得到如下输出
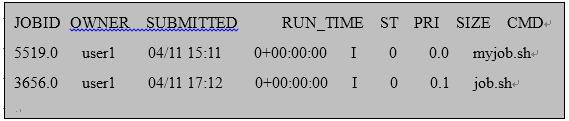
图1-3 hep_q输出示例 如上所示,JOBID表示作业号,OWNER表示作业所属用户,SUBMITTED表示作业提交时间,RUN_TIME表示作业运行时间,ST表示作业当前状态,PRI表示作业优先级,SIZE表示作业占用虚拟内存大小,CMD表示作业程序名。
(2)根据作业ID查询作业状态。例如,查询作业ID为3745232.1的作业,执行如下命令:
作业删除
(1)根据作业ID删除作业,并支持多个作业同时删除。例如,删除作业3745232,3745233.0,执行命令:
$ hep_rm 3745232 3745233.0(2)依据用户删除作业。例如,删除当前用户所有作业,执行命令:
$ hep_rm -a
Step 3.2 Slurm作业
准备作业脚本
使用自己喜欢的编辑器如vim或者emacs编辑待提交的作业脚本。样例作业脚本可在如下路径中找到 /cvmfs/common.ihep.ac.cn/software/slurm_sample_script
$ ssh <AFS_user_name>@lxlogin.ihep.ac.cn $ cd /cvmfs/common.ihep.ac.cn/software/slurm_sample_script $ ls -lht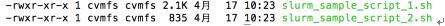
图 1-4 slurm模板目录 最简单的样例脚本为:
$ cat slurm_sample_script_2.sh
图 1-5 slurm作业脚本模板 在脚本中:
(1) 定义好需要的变量,如VAR1,VAR2;
(2) 如果需要运行自己的脚本程序,则使用srun命令来启动,并且将/path/to/your/script修改为自己的脚本文件名;
(3) 如果需要运行并行程序,则首先使用srun命令来触发资源分配,接下来可以使用mpiexec命令来运行并行程序。同样地,/path/to/your/mpi_program需要修改为自己的并行程序路径名。
提交作业
脚本文件编辑好以后,准备提交,所使用的提交命令如下所示:
$ hep_sub -slurm -part <partition_name> -g <group_name> -np <cpu_core_number> slurm_sample_script_2.sh其中:
(1)
是队列名称,可使用的队列名称可使用hep_clus命令查到: $ hep_clus -slurm得到的结果如下所示:
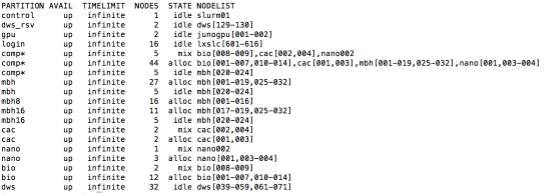
图 1-6 hep_clus输出示例 可使用的队列名称如第一列所示。如果不确定自己需要哪个队列,可使用选项向comp队列提交作业,这是集群的默认队列。
(2)
是作业所属的组名。例如,如果待提交的作业是属于BES实验的offline组,则使用-goffline来指定作业所属组。 (3)
是作业运行所需要的CPU核数。例如,如果需要30个CPU核,则使用-np30选项来指定。 如上所述,如果要向队列comp提交一个作业脚本文件slurm_sample_script_2.sh,该作业属于offline组,并且需要30个CPU核的话,所使用的提交命令为:
$ hep_sub -slurm -part comp -g offline -np 30 slurm_sample_script_2.sh注意事项:
队列名和作业所属组名必须提供,否则作业提交不会成功。
查看作业状态
作业提交以后,hep_sub会返回一个作业id号,该id号可以用来查看作业,所使用的命令为:
$ hep_q -slurm -i <job_id>其中
即为hep_sub返回的作业id号。 获取作业结果
作业运行结束后,若没有指定输出目录,默认的作业结果将会存放在用户提交作业的目录下,输出文件格式为
.out。其中, 是作业id号。例如如果作业id号为1234,那么输出文件名称为1234.out。