3.2.2 Slurm计算集群使用方法
3.2.2.1 Slurm CPU计算集群使用方法
CPU集群简介
- 目前CPU集群的用户分别来自以下组,各组的应用及联系人如下所示
| group(组) | 应用 | 计算联系人 |
|---|---|---|
| mbh | 天体黑洞研究 | 李彦荣 |
| bio | 第一性原理计算 | 赵丽娜 |
| heps | HEPS加速器设计 | 焦毅,段哲 |
| cepcmpi | CEPC加速器设计 | 张源,王毅伟 |
| alicpt | AliCPT实验 | 李虹 |
| bldesign | HEPS光束线站 | 赵海峰 |
| raq | 量子化学,分子动力学 | 蓝建慧 |
| apg | 加速器设计 | 许海生 |
| pwfa | 等离子加速 | 曾明 |
- 各组均使用独立的计算资源,各组的资源分区、作业队列、计算节点如下所示:
| partition(节点分区) | QOS(作业队列) | account / group(组) | worker nodes(计算节点) |
|---|---|---|---|
| mbh,mbh16 | regular | mbh | 16个节点,共256个CPU核 |
| cac | regular | cac | 7个节点,共336个CPU核 |
| biofastq | regular | bio | 11个节点,共264个CPU核 |
| heps | regular,advanced | heps | 34个节点,共1224个CPU核 |
| hepsdebug | hepsdebug | heps | 1个节点,共36个CPU核 |
| cepcmpi | regular | cepcmpi | 36个节点,共1696个CPU核 |
| ali | regular | alicpt | 44个节点,共2368个CPU核 |
| bldesign | blregular | bldesign | 3个节点,共108个CPU核 |
| raq | raqregular,raqacc | raq | 12个节点,共672个CPU核 |
| apg | apgregular | apg | 12个节点,共768个CPU核 |
| pwfadebug | spubpwfa | pfwa | 1个节点,共24个CPU核 |
- 作业队列qos的资源使用限制如下所示:
| QOS | 作业最大运行时间 | 最大可提交作业数量 | 最大资源使用量 | 优先级 |
|---|---|---|---|---|
| regular | 60天 | 每个用户4000个,每个组8000个 | - | 低 |
| advanced | 60天 | - | - | 高 |
| hepsdebug | 30分钟 | 每个用户100个 | - | 中 |
| blregular | 30天 | 每个用户200个,每个组1000个 | - | 低 |
| apgregular | - | - | - | 低 |
| raqregular | - | 每个用户100个 | 280个CPU核 | 高 |
| raqacc | - | 每个用户50个 | 112个CPU核 | 低 |
| spubpwfa | - | - | - | 低 |
Step 0 准备集群账号及使用授权
已建立好集群账号并获得slurm集群使用授权的用户可跳过此步。
从未申请过集群帐号的新用户:
- 账号申请页面:申请页面
- 若新用户申请的组被Slurm CPU集群支持,新用户将自动获得集群授权
- 若新用户申请的组未被Slurm CPU集群支持,有两种方法获得授权:
- 新用户申请加入被Slurm CPU集群支持的组,从而获得授权,具体可参考下一章节“已有帐号但未授权的用户”
- 若新用户无法加入被Slurm CPU集群支持的组,可以选择租用公共计算平台,具体可参考 公共计算平台的使用简介
已有帐号但未授权的用户:
若未授权,用户使用
sbatch命令提交作业时将遇到如下报错:sbatch: error: Batch job submission failed: Invalid account or account/partition combination specified目前已提供用户自助申请方式获得授权,自助申请流程如下
使用SSO统一认证方式登录 http://ccsinfo.ihep.ac.cn
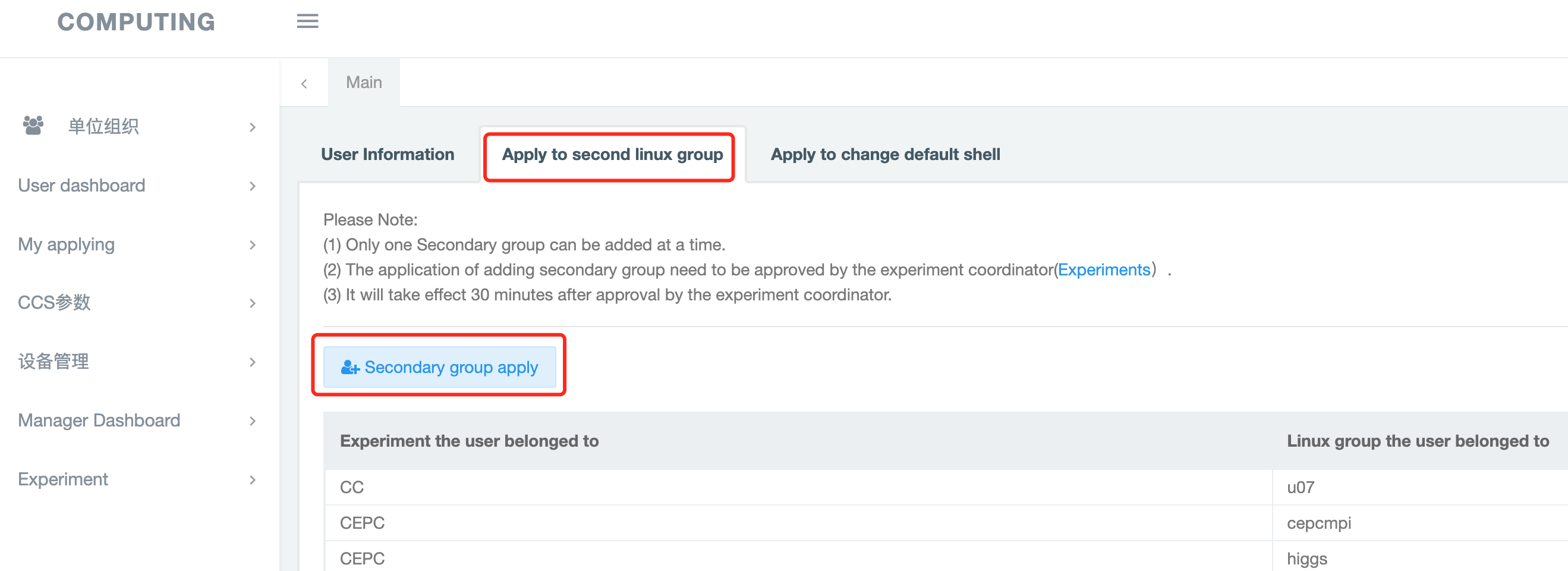
点击”Apply to second linux group“ -> "Secondary group apply",选择申请加入的组
- 可申请加入的组请参考:Slurm CPU集群简介
- 若未发现可申请的组,可考虑租用高能所公共计算平台
填写好申请理由、选择好组后点击“确定”提交申请
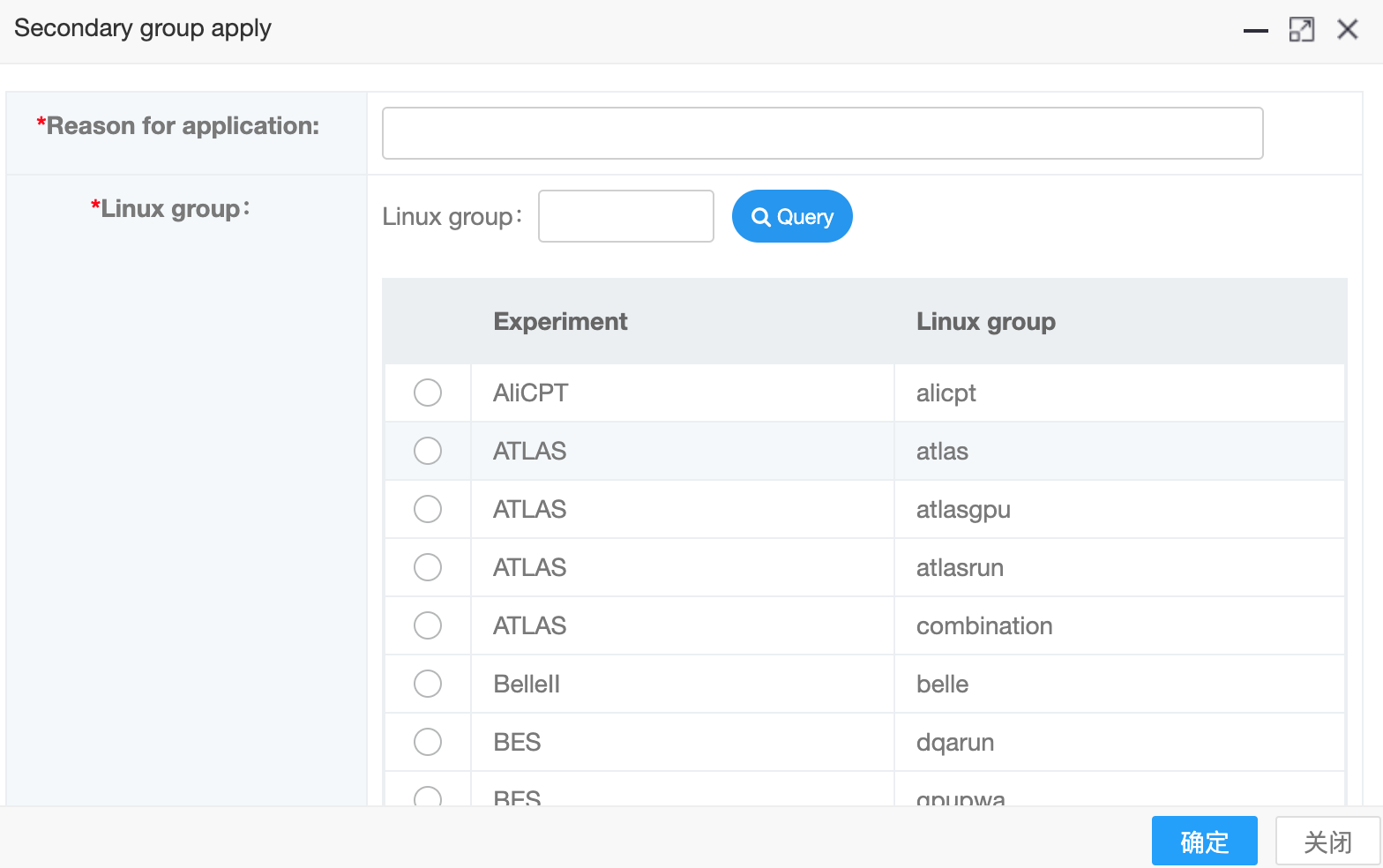
提交后,由组所在的实验计算联系人负责审批、完成授权。
- 各实验计算联系人可参考:实验应用及相关负责人
Step1 准备作业脚本
请不要使用/afs或/workfs2下的目录作为数据读写目录,由于计算节点无法写入这两个目录,提交的作业会立刻报错退出
- 每个集群帐号在创建时,都会默认有三个存储目录:/afs,/workfs2,/scratchfs
| 存储目录 | 默认使用限额(quota) | 用途说明 | 是否有备份 |
|---|---|---|---|
| /afs | 500MB | 默认home目录 | 有 |
| /workfs2 | 5GB,5万个文件 | 代码备份目录 | 有 |
| /scratchfs | 500GB,20万个文件 | 数据目录 | 无 |
- 除上述三个目录外,各实验有专用的数据目录,具体可参考:
- 作业提交目录推荐在数据目录中,避免计算节点无法写入/afs或/workfs2而产生报错
- 若有需要将默认home目录(/afs)修改至其他非/scratchfs的数据目录,请联系HelpDesk修改
使用自己喜欢的编辑器(如vim)编辑待提交的作业脚本。
作业脚本的样例可在如下目录中找到:
/cvmfs/slurm.ihep.ac.cn/slurm_sample_script
说明:作业脚本的样例存储在CVMFS文件系统中,CVMFS的使用方法如下所示:
# 登录到登录节点,其中<user_name>为集群账号 > ssh <user_name>@lxlogin.ihep.ac.cn # 找到样例脚本所在的目录 > cd /cvmfs/slurm.ihep.ac.cn/slurm_sample_script # 查看样例脚本 > ls slurm_sample_script*.sh slurm_sample_script_cpu.sh slurm_sample_script_gpu.sh
- 编辑样例脚本,得到可运行的作业脚本
# 显示样例脚本内容
> cat slurm_sample_script_cpu.sh
#! /bin/bash
#================= Part 1 : job parameters ============
#SBATCH --partition=mbh
#SBATCH --account=mbh
#SBATCH --qos=regular
#SBATCH --ntasks=16
#SBATCH --mem-per-cpu=2GB
#SBATCH --job-name=test_job
#============== Part 2 : job workload ===================
NP=$SLURM_NTASKS
# source your environment file if exists
# replace /path/to/your/env_file with your real env file path
source /path/to/your/env_file
# replace /path/to/your/mpi_program with your real MPI program path
mpirun -np $NP /path/to/your/mpi_program
作业脚本说明:
作业脚本通常由两部分组成:
作业运行参数,以#SBATCH为开头,指明作业运行的参数
作业运行内容,通常为可执行程序,如可执行脚本、MPI程序等
作业运行参数--partition, --account, --qos为必选项,必须指明,否则作业会提交失败。
- --mem-per-cpu用于申请每个CPU核可使用的内存数量
- --ntasks用于申请可使用的CPU数量
- --job-name用于指定作业名称,用户可以自定义
Step2 提交作业
脚本文件编辑好以后,准备提交,所使用的提交命令如下所示:
# lxlogin.ihep.ac.cn为集群登录节点, 其中<user_name>为用户名
$ ssh <user_name>@lxlogin.ihep.ac.cn
# 使用sbatch命令提交作业
$ sbatch slurm_sample_script_1.sh
Step3 查看作业
查看单个作业
作业提交以后,
sbatch会返回一个作业id号,该id号可以用来查看作业,所使用的命令为:# 使用命令sacct,其中<jobid>为作业id号 $ sacct -j <jobid>
查看用户已提交的所有作业
若要查看用户在当天0:00后提交的作业,可使用命令:
# 使用命令sacct # -u选项后接用户集群账号 $ sacct -u <user_name>若要查看用户在某天以后提交的所有作业,可以使用命令:
# 使用命令sacct # -u选项后接用户集群账号 # --starttimes是查询的起始时间,格式为YYYY-MM-DD $ sacct -u <user_name> --starttime='YYYY-MM-DD'
Step4 获取作业运行结果
作业运行结束后,可查看作业运行结果。
- 若没有指定输出文件:默认的作业结果将会存放在用户提交作业的目录下,输出文件格式为
<job_id>.out。其中,<job_id>是作业id号。- 例如如果作业id号为
1234, 那么输出文件名称为1234.out。
- 例如如果作业id号为
- 若指定了输出文件,则可在指定的输出文件看到运行结果。
- 若作业运行的可执行文件或程序重定向了输出文件,则可在重定向后的输出文件中找到运行结果。
Step5 取消作业
若要取消已经提交的作业,可使用如下命令:
# 或者使用命令scancel
# <job_id> 是要取消的作业id号,可以使用sacct -u <user_name>查找作业id
$ scancel <job_id>
Step6 查看集群状态
若要查看集群中有哪些partition及partition中的资源使用情况,可使用命令:
# 使用命令sinfo
$ sinfo
3.2.2.2 Slum GPU集群使用方法
GPU集群简介
- 目前可以使用Slurm GPU集群的组如下所示:
| group | 应用 | 计算负责人 |
|---|---|---|
| lqcd | 格点QCD | 陈莹,宫明 |
| gpupwa | 分波分析 | 刘北江,董燎原 |
| junogpu | 中微子分析 | 罗武鸣 |
| mlgpu | BESIII机器学习 | 张瑶 |
| higgsgpu | CEPC GPU应用 | 李刚 |
| bldesign | HEPS光束线站GPU应用 | 赵海峰 |
| ucasgpu | UCAS机器学习 | 吕晓睿 |
| pqcd | 微扰QCD计算 | 李钊 |
| cmsgpu | CMS机器学习 | 张华桥,陈明水 |
| neuph | 中微子理论和唯象学 | 李玉峰 |
| atlasgpu | ATLAS机器学习 | ATLAS实验负责人 |
| lhaasogpu | LHAASO机器学习 | LHAASO实验负责人 |
| herdgpu | HERD机器学习 | HERD实验负责人 |
| qc | 量子计算 | CC实验负责人 |
| lhcbgpu | LHCB机器学习 | 李一鸣 |
- GPU集群目前有4个资源分区partition, 每个partition对应的队列(QOS)和组(account)如下所示:
| 资源分区(partition) | 队列(qos) | 组(account/group) | 作业资源限制 | 计算资源 |
|---|---|---|---|---|
| lgpu | long | lqcd | QOS long - 每个作业运行时间不超过30天 - 每个作业每CPU核最大可使用40GB内存 - 每组作业数量(运行+排队)不超过64个 |
- 共1个节点,每个节点可用360GB 内存 - 共8张GPU卡,型号为NVIDIA V100 nvlink - 共36个CPU核 |
| gpu | normal, debug | lqcd, junogpu, mlgpu, higgsgpu |
QOS normal - 每个作业运行时间不超过48小时 - 每个作业每CPU核最大可使用40GB内存 - 每组作业数量(运行+排队)不超过512个 - 每组可使用的GPU卡数量不超过128张 - 每组最多可使用432个CPU核 - 每组可使用的最大内存总量为5TB - 每个用户作业数量(运行+排队)不超过96个 - 每个用户可使用的GPU卡数量不超过64张 - 每个用户最多可使用216个CPU核 - 每个用户可使用的最大内存总量为2TB QOS debug - 作业运行时间不超过15分钟 - 每个作业每CPU核最大可使用40GB内存 - 每组作业数量(运行 + 排队)不超过256个 - 每组可使用的GPU卡不超过64张 - 每组最多可使用108个CPU核 - 每组可使用的最大内存总量为1TB - 每个用户作业数量(运行+排队)不超过24个 - 每个用户可使用的GPU卡不超过16张 - 每个用户最多可使用54个CPU核 - 每个用户可使用的最大内存总量为512GB QOS debug 优先级高于QOS normal优先级 |
- 共24个节点,其中: - 23个节点,每个节点可用内存360GB ; - 1个节点,每个节点可用内存为240GB - 共183张GPU卡,其中 - 182张 NVIDIA V100 nvlink GPU卡 - 1张 NVIDIA A100 PCIe GPU卡 - 共892个CPU 核 |
| gpu | pwanormal, debug | gpupwa | QOS pwanormal - 每个作业运行时间不超过48小时 - 每个作业每CPU核最大可使用40GB内存 - 每组作业数量(运行+排队)不超过512个 - 每组可使用的GPU卡数量不超过128张 - 每组最多可使用432个CPU核 - 每组可使用的最大内存总量为5TB - 每个用户作业数量(运行+排队)不超过38个 - 每个用户可使用的GPU卡数量不超过10张 - 每个用户最多可使用32个CPU核 - 每个用户可使用的最大内存总量为600GB QOS debug - 作业运行时间不超过15分钟 - 每个作业每CPU核最大可使用40GB内存 - 每组作业数量(运行 + 排队)不超过256个 - 每组可使用的GPU卡不超过64张 - 每组最多可使用108个CPU核 - 每组可使用的最大内存总量为1TB - 每个用户作业数量(运行+排队)不超过24个 - 每个用户可使用的GPU卡不超过16张 - 每个用户最多可使用54个CPU核 - 每个用户可使用的最大内存总量为512GB QOS debug 优先级高于QOS pwanormal优先级 |
- 共24个节点,其中: - 23个节点,每个节点可用内存360GB ; - 1个节点,每个节点可用内存为240GB - 共183张GPU卡,其中 - 182张 NVIDIA V100 nvlink GPU卡 - 1张 NVIDIA A100 PCIe GPU卡 - 共892个CPU 核 |
| gpu | debug | atlasgpu, lhaasogpu, herdgpu, qc,lhcbgpu | QOS debug - 作业运行时间不超过15分钟 - 每个作业每CPU核最大可使用40GB内存 - 每组作业数量(运行 + 排队)不超过256个 - 每组可使用的GPU卡不超过64张 - 每组最多可使用108个CPU核 - 每组可使用的最大内存总量为1TB - 每个用户作业数量(运行+排队)不超过24个 - 每个用户可使用的GPU卡不超过16张 - 每个用户最多可使用54个CPU核 - 每个用户可使用的最大内存总量为512GB |
- 共24个节点,其中: - 23个节点,每个节点可用内存360GB ; - 1个节点,每个节点可用内存为240GB - 共183张GPU卡,其中 - 182张 NVIDIA V100 nvlink GPU卡 - 1张 NVIDIA A100 PCIe GPU卡 - 共892个CPU 核 |
| gpu | cmsnormal,debug | cmsgpu | QOS cmsnormal - 每个作业运行时间不超过48小时 - 每个作业每CPU核最大可使用40GB内存 - 每组作业数量(运行+排队)不超过128个 - 每组可使用的GPU卡数量不超过17张 - 每组最多可使用72个CPU核 - 每组可使用的最大内存总量为720GB - 每个用户作业数量(运行+排队)不超过36个 - 每个用户可使用的GPU卡数量不超过9张 - 每个用户最多可使用36个CPU核 - 每个用户可使用的最大内存总量为360GB QOS debug - 作业运行时间不超过15分钟 - 每个作业每CPU核最大可使用40GB内存 - 每组作业数量(运行 + 排队)不超过256个 - 每组可使用的GPU卡不超过64张 - 每组最多可使用108个CPU核 - 每组可使用的最大内存总量为1TB - 每个用户作业数量(运行+排队)不超过24个 - 每个用户可使用的GPU卡不超过16张 - 每个用户最多可使用54个CPU核 - 每个用户可使用的最大内存总量为512GB |
- 共24个节点,其中: - 23个节点,每个节点可用内存360GB ; - 1个节点,每个节点可用内存为240GB - 共183张GPU卡,其中 - 182张 NVIDIA V100 nvlink GPU卡 - 1张 NVIDIA A100 PCIe GPU卡 - 共892个CPU 核 |
| gpu | blnormal, debug | bldesign | QOS blnormal - 每个作业运行时间不超过48小时 - 每个作业每CPU核最大可使用40GB内存 - 每组作业数量(运行+排队)不超过32个 - 每组可使用的GPU卡数量不超过16张 - 每组最多可使用72个CPU核 - 每组可使用的最大内存总量为720GB - 每个用户作业数量(运行+排队)不超过16个 - 每个用户可使用的GPU卡数量不超过8张 - 每个用户最多可使用36个CPU核 - 每个用户可使用的最大内存总量为360GB QOS debug - 作业运行时间不超过15分钟 - 每个作业每CPU核最大可使用40GB内存 - 每组作业数量(运行 + 排队)不超过256个 - 每组可使用的GPU卡不超过64张 - 每组最多可使用108个CPU核 - 每组可使用的最大内存总量为1TB - 每个用户作业数量(运行+排队)不超过24个 - 每个用户可使用的GPU卡不超过16张 - 每个用户最多可使用54个CPU核 - 每个用户可使用的最大内存总量为512GB QOS debug 优先级高于QOS blnormal优先级 |
- 共24个节点,其中: - 23个节点,每个节点可用内存360GB - 1个节点,每个节点可用内存为240GB - 共183张GPU卡,其中 - 182张 NVIDIA V100 nvlink 32G GPU卡 - 1张 NVIDIA A100 PCIe 40G GPU卡 - 共892个CPU 核 |
| ucasgpu | ucasnormal | ucasgpu | QOS ucasnormal - 每个作业运行时间不超过48小时 - 每个作业每CPU核最大可使用40GB内存 - 每组作业数量(运行+排队)不超过100个 - 每组可使用的GPU卡数量不超过16张 - 每组最多可使用36个CPU核 - 每组可使用的最大内存总量为720GB - 每个用户作业数量(运行+排队)不超过10个 - 每个用户可使用的GPU卡数量不超过6张 - 每个用户最多可使用18个CPU核 - 每个用户可使用的最大内存总量为480GB |
- 共1个节点 -每个节点可用360GB 内存 - 共8张GPU卡 -型号为NVIDIA V100 nvlink 32G - 共36个CPU核 |
| pqcdgpu | pqcdnormal | pqcd | QOS pqcdnormal - 每个作业运行时间不超过72小时 - 每个作业每CPU核最大可使用32GB内存 - 每组作业数量(运行+排队)不超过100个 - 每组可使用的GPU卡数量不超过16张 - 每组最多可使用20个CPU核 - 每组可使用的最大内存总量为180GB - 每个用户作业数量(运行+排队)不超过20个 - 每个用户可使用的GPU卡数量不超过8张 - 每个用户最多可使用20个CPU核 - 每个用户可使用的最大内存总量为180GB |
- 共1个节点 -每节点可用180GB内存 - 共5张GPU卡 -型号为NVIDIA V100 PCI-e 32G - 共20个CPU核 |
| neuph | neuphnormal | neuph | - | - 共2个节点 -每节点可用360GB内存 - 共5张GPU卡 -型号为NVIDIA A100 PCI-e 40GB GPU 卡 - 共96个CPU核 |
| gpupwa | pwadedicate, pwadebug | gpupwa | QOS pwadedicate - 每个作业运行时间不超过48小时 - 每个作业每CPU核最大可使用40GB内存 - 每个用户作业数量(运行+排队)不超过12个 - 每个用户可使用的GPU卡数量不超过8张 - 每个用户最多可使用16个CPU核 - 每个用户可使用的最大内存总量为640GB QOS pwadebug</font> - 每个作业运行时间不超过15分钟 - 每个作业每CPU核最大可使用40GB内存 - 每个用户作业数量(运行+排队)不超过16个 - 每个用户可使用的GPU卡数量不超过8张 - 每个用户最多可使用32个CPU核 - 每个用户可使用的最大内存总量为640GB QOS pwadebug优先级高于QOS pwadedicate**</font> |
- 共5个节点 -每个节点可用740GB 内存 - 共40张GPU卡 -型号为NVIDIA A100 PCI-e 40G - 共320个CPU核 |
| 资源分区(partition) | 队列(qos) | 组(account/group) | 作业资源限制 | 计算资源 |
debug队列特别说明:
- debug队列适合运行的作业类型
- 开发过程中的代码测试
- 运行时间较短
- 对于mlgpu和higgsgpu组运行时间较短、希望被较快调度的作业,推荐提交到debug队列中
- 其他组别,如gpupwa组的作业,75%的作业运行时长小于15分钟,也可以提交到该队列中
Step1 申请集群账号
- 已建立好集群账号并获得slurm集群使用授权的用户可跳过此步。
从未申请过集群帐号的新用户:
- 账号申请页面:申请页面
- 若新用户申请的组被Slurm GPU集群支持,新用户将自动获得集群授权
- 若新用户申请的组未被Slurm GPU集群支持,有两种方法获得授权:
- 新用户申请加入被Slurm GPU集群支持的组,从而获得授权,具体可参考下一章节“已有帐号但未授权的用户”
- 若新用户无法加入被Slurm GPU集群支持的组,可以选择租用公共计算平台,具体可参考 公共计算平台的使用简介
已有集群帐号但未授权的用户:
若未授权,用户使用
sbatch命令提交作业时将遇到如下报错:sbatch: error: Batch job submission failed: Invalid account or account/partition combination specified目前已提供用户自助申请方式获得授权,自助申请流程如下
- 使用SSO统一认证方式登录 http://ccsinfo.ihep.ac.cn
点击”Apply to second linux group“ -> "Secondary group apply",选择申请加入的组
- 可申请加入的组请参考:Slurm GPU集群简介
- 若未发现可申请的组,可考虑租用高能所公共计算平台
填写好申请理由、选择好组后点击“确定”提交申请
- 提交后,由组所属的实验计算联系人负责审批、完成授权
- 各实验计算联系人可参考:实验应用及相关负责人
Step2 准备运行软件
- lqcd组使用的运行软件可放在AFS专用的卷中,具备写权限的用户可将编译好的软件放入目录
/afs/ihep.ac.cn/soft/lqcd/,目前空间设置为100GB - 一些公用的软件安装在
/cvmfs/slurm.ihep.ac.cn/centos7.9,/cvmfs/slurm.ihep.ac.cn/centos7.8中,可自行查找 其他未在/cvmfs/slurm.ihep.ac.cn/中安装的软件:
- gpupwa, junogpu, mlgpu, higgsgpu, bldesign组请将运行软件安装在专用的
/hpcfs目录下,各组详细的目录路径见Step3 - 其他组可安装在
/scratchfs下,或者实验专用的存储目录。
- gpupwa, junogpu, mlgpu, higgsgpu, bldesign组请将运行软件安装在专用的
如有特殊需求,请联系集群管理员
Step3 准备数据读写目录
请不要使用/afs或/workfs2下的目录作为数据读写目录,由于计算节点无法写入这两个目录,提交的作业会立刻报错退出
GPU服务器为以下组提供专门的共享文件系统目录用于数据读写
- lqcd组目录为:
/hpcfs/lqcd/qcd/ - gpupwa组目录为:
/hpcfs/bes/gpupwa/ - junogpu组目录为:
/hpcfs/juno/junogpu/ - mlgpu组目录为:
/hpcfs/bes/mlgpu/ - higgsgpu组目录为:
/hpcfs/cepc/higgs/ - bldesign组目录为:
/hpcfs/hpes/bldesign/
- lqcd组目录为:
- 其他组可使用本实验的专用数据目录,可参考Lustre数据目录
- 若所属实验没有专用的数据目录,可使用/scratchfs
- 如果作业有输出或输入数据,请写入所属组别下的个人目录中。例如,如果是lqcd组的用户,假设用户的AFS账号为
zhangsan,则个人目录为/hpcfs/lqcd/qcd/zhangsan/ - 非上述组的gpu用户,可使用
/scratchfs或实验专用的目录作为数据目录。/scratchfs的目录结构为:/scratchfs/<experiment_name>/<user_name>。例如,假设PQCD有一个用户zhangsan,那么他在/scratchfs下的存储目录为/scratchfs/pqcd/zhangsan。
Step4 准备待提交作业脚本
待提交的作业脚本为bash脚本,该脚本可分为两个部分:
- 运行参数部分:以
#SBATCH为开头,用于指定partition,qos,account,资源(CPU/GPU/内存)数量、输出路径等参数 - 作业负载部分:作业要运行的软件、可执行的脚本等
特别注意!!:
#SBATCH开头的行与#!开头的行之间不要加任何命令!!可以加空白行或者注释行,如果加入命令,将会导致以
#SBATCH开头的脚本运行参数解析不正确,作业无法得到申请的资源而运行失败。
- 运行参数部分:以
样例脚本如下所示:
#! /bin/bash
######## Part 1 #########
#SBATCH --partition=gpu
#SBATCH --qos=normal
#SBATCH --account=lqcd
#SBATCH --ntasks=2
#SBATCH --mem-per-cpu=4096
#SBATCH --gpus=v100:1
#SBATCH --job-name=test
######## Part 2 ######
# Replace the following lines with your real workload
# list the allocated hosts
srun -l hostname
sleep 180
作业运行参数的说明:
- #SBATCH 为作业脚本参数,用于指定作业运行参数、申请资源数量等等,不是注释,请勿删除
- 各组对应的--partition,-- account,--qos选项
组(group) 作业类型 --partition --account(通常与group名称相同) --qos lqcd 长作业 lgpu lqcd long lqcd,higgsgpu,mlgpu,junogpu 普通作业 gpu lqcd,higgsgpu,mlgpu,junogpu normal gpupwa 普通作业 gpu gpupwa pwanormal gpupwa 普通作业 gpupwa gpupwa pwadedicate gpupwa debug作业 gpupwa gpupwa pwadebug Lqcd,gpupwa,higgsgpu,mlgpu,
junogpu,cmsgpu,atlasgpu,lhcbgpu, lhaasogpu,qcdebug作业 gpu Lqcd,gpupwa,higgsgpu,mlgpu,
junogpu,cmsgpu,atlasgpu,lhcbgpu, lhaasogpu,qcdebug bldesign 普通作业 gpu bldesign blnormal bldesign debug作业 gpu bldesign bldebug ucasgpu 普通作业 ucasgpu ucasgpu ucasnormal pqcd 普通作业 pqcdgpu pqcd pqcdnormal cmsgpu 普通作业 gpu cmsgpu cmsnormal neuph 普通作业 neuph neuph neuphnormal
- --mem-per-cpu选项用于指定需要的内存数量
- 如果不指定,默认为每个CPU core分配4GB内存
- 每CPU core最大可分配内存数可参考集群资源、队列和组别说明,请大家根据实际应用指定内存用量
- --ntasks选项用于指定所需的cpu核数量
- 例如:
#SBATCH --ntasks=20申请了20个CPU核- --gpus选项用于指定所需的GPU卡类型及数量,例如:
#SBATCH --gpus=v100:1申请使用1张v100 GPU卡#SBATCH --gpus=a100:1申请使用1张a100 GPU卡#SBATCH --gpus=1申请使用一张GPU卡,可以是任何可用的型号- --job-name选项用于指定作业名称,用户可自定义
#SBATCH --time的特别说明
- 在作业脚本中使用
--time选项,有可能减少作业等待时间,尤其是作业数量较多的gpupwa组- 调度系统会根据
--time选项说明的作业运行时间,插空运行作业- 在作业脚本中使用
--time选项的方法如下所示:# To tell how long does it take to finish the job, e.g.: 2 hours in the following line #SBATCH --time=2:00:00 # for the jobs will be run more than 24 hours, use the following time format # e.g. : this job will run for 1 day and 8 hours #SBATCH --time=1-8:00:00
- 对于不清楚作业运行的用户,可参考如下的统计结果:
组 运行时长 概率 gpupwa <= 1 hour 90.43% lqcd <= 32 hours 90.37% junogpu <= 12 hours 91.24%
- mlgpu和higgsgpu组的作业数量较少,可以将作业提交到debug队列中,暂时不使用
--time选项- 如果作业运行超时,调度系统会自动清理超时作业
Step5 提交作业
- 登录节点
# 请使用ssh命令登录
$ ssh <username>@lxlogin.ihep.ac.cn
# 其中<username>为用户的集群账号
- 提交作业命令为:
# command to submit a job
$ sbatch <job_script.sh>
# <job_script.sh> is the name of the script,e.g: v100_test.sh, then the command is:
$ sbatch v100_test.sh
# There will be a jobid returned as a message if the job is submitted successfully
Step6 查看作业
- 作业查看命令为:
# command to check the job queue
$ squeue
# command to check the jobs submitted by user
$ sacct
Step7 取消作业
- 作业取消命令为:
# command to cancel the job
$ scancel <jobid>
# <jobid> can be found using the command sacct
3.2.2.3 公用计算平台使用方法
公用计算平台简介
公用计算平台是由计算中心建设的、旨在为所内用户提供的、可租用的并行计算服务平台。该平台使用Slurm调度系统,提供的资源如下所示。
计算节点资源
| 节点分区(partition) | 节点资源 |
|---|---|
| spub | 共20个节点,其中: - 16个CPU节点:每节点56个CPU核,240GB内存 - 3个CPU节点:每节点36个CPU核,110GB内存 - 1个GPU节点:每节点48个CPU核,360GB内存,4张NVIDIA A100 PCI-e 40GB GPU卡 |
- 存储资源
| 挂载点 | 总容量 | 使用限制 |
|---|---|---|
| /ihepfs | 400TB | 默认限制为每用户500GB,30万个文件 可根据实际需求调整 |
- 商业软件
| 软件名称 | license数量 |
|---|---|
| matlab parallel toolbox | 512 |
- 用户组(account),资源分区(partition),队列(qos)如下表所示
| 用户组(account) | 节点分区(partition) | 队列(qos) |
|---|---|---|
| 与组名(group)相同 | spub | 根据用户需求建立 |
说明:
队列的设置可根据实际情况调整。
Step1 准备集群账号
- 若无计算集群账号,请参考申请集群帐号
- 若已有计算集群账号,可跳过此步骤
Step2 申请公用计算平台机时
- 请在页面公共计算平台简介 下载 “公用计算平台使用申请表”并发送给yanran@ihep.ac.cn,计算中心将有专人对接计算需求
- 需求对接完成后,平台管理员将根据申请为用户初始化集群环境,包括:
- 设置作业队列
- 建立存储目录
- 安装软件环境
- 根据用户需求完成集群环境初始化后,用户可提交作业运行,作业提交及运行方法可参考Step3 - Step7
Step3 准备数据
- 申请通过后,用户可用专用目录存储输入/输出数据,数据目录结构为
/ihepfs/<experiment_name>/<user_name> - 例如:用户
zhangsan所属的实验为SPUB, 那么他的存储目录为/ihepfs/SPUB/zhangsan
Step4 准备作业脚本
- 用户收到的申请邮件中会指明account及qos
- 用户可使用如下样例脚本,并修改相应选项值
<account>, <qos>使用邮件中指定的值替换<experiment_name>,<user_name>使用实验名及用户名替代%j为作业ID号,在作业运行过程中由系统自动生成
$ cat spub_slurm_sample.sh
#! /bin/bash
#================= Part 1 : job parameters ========================
#SBATCH --partition=spub
#SBATCH --account=<account>
#SBATCH --qos=<qos>
#SBATCH --job-name=sample
#SBATCH --ntasks=16
#SBATCH --mem-per-cpu=2GB
#SBATCH --output=/ihepfs/<experiment_name>/<user_name>/job-%j.out
#============ Part 2 : Job workload =====================
#===== Run your programs =====
# source your ENV settings first
NP=8
mpirun -n $NP my_mpi_program
Step5 提交作业
$ ssh <user_name>@lxlogin.ihep.ac.cn
# 使用sbatch命令提交作业,会返回该作业id
$ sbatch spub_slurm_sample.sh
Step6 查看作业
# 查看队列中用户zhangsan的作业
$ squeue -u zhangsan
# 使用作业id 1008163 查看作业
$ sacct -j 1008163
# 查看今天用户zhangsan提交的所有作业
$ sacct -u zhangsan
# 查看用户zhangsan自2021-07-18后提交的所有作业
$ sacct -u zhangsan --starttime=2021-07-18
Step7 删除作业
# 删除ID为1008163的作业
$ scancel 1008163
# 删除用户zhangsan的所有作业
$ scancel -u zhangsan
常见问题Q&A
1. 能否只申请使用公用计算平台的软件或存储资源?
可以,可根据实际需求申请资源。
2. 提供的样例脚本不能满足我的需求,要怎么办?
请联系平台管理员,可根据用户需求提供样例脚本。
3. 费用如何计算?
可咨询计算需求对接专员:嫣然(yanran@ihep.ac.cn)